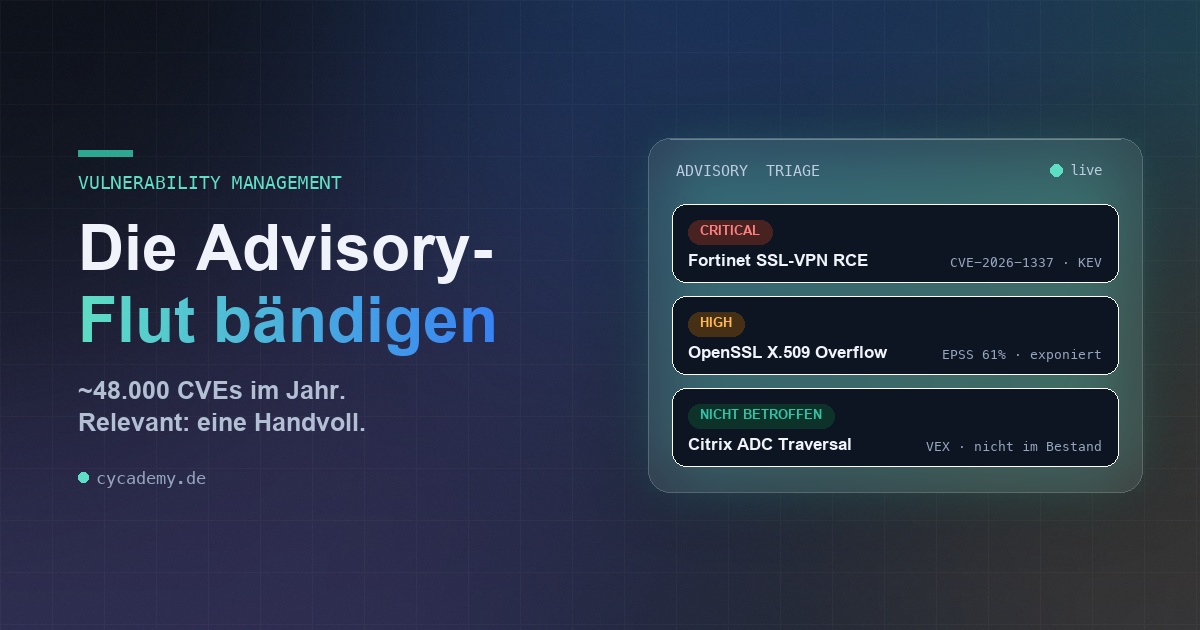
Jede Woche erscheinen Hunderte neuer Security Advisories — Sicherheitsmeldungen vom BSI, von CERT-Bund, von Herstellern, aus der NVD. Die eigentliche Arbeit beginnt aber erst nach dem Eingang: Betrifft uns das? Wie dringend? Wer kümmert sich? Und können wir gegenüber Aufsicht und Revision belegen, dass wir richtig gehandelt haben?
Genau an dieser Übersetzung von „Meldung“ zu „begründeter, dokumentierter Entscheidung“ scheitern heute die meisten Teams. Nicht aus Unfähigkeit — sondern weil sie einen Prozess mit der Hand fahren, der längst Maschinengeschwindigkeit verlangt.
Security Advisories sind kein technisches, sondern ein organisatorisches Problem geworden. Die Menge ist nicht mehr manuell zu bewältigen, die Regulatorik macht systematisches Handeln zur Pflicht — und die Beweislast liegt beim Betreiber.
Dieser Beitrag zeigt, warum das so ist, was der Gesetzgeber 2026 konkret verlangt, wie ein belastbarer Prozess aussieht — und woran Sie messen, ob Ihrer reif ist.
Von der Flut zum Fokus: das eigentliche Mengenproblem
Allein 2025 wurden über 48.000 neue CVEs veröffentlicht — ein Rekordwert und rund 20 % mehr als im Vorjahr, Tendenz weiter steigend. Die entscheidende Zahl daneben: Nur ein kleiner Bruchteil davon wird je nachweislich ausgenutzt. Der ganze Rest ist, aus Sicht Ihres Unternehmens, Rauschen, das den Blick auf die wenigen wirklich gefährlichen Meldungen verstellt.
Der Advisory-Trichter
Von der Flut zur Handlung. Schematisch — die Anteile hängen von Branche und Pflege des Asset-Katalogs ab.
Die Kunst des Advisory-Managements ist nichts anderes als dieser Trichter: aus dem oberen, breiten Rauschen verlässlich und nachvollziehbar das untere, schmale Signal herauszufiltern — schnell genug, um Fristen zu halten, und belegbar genug, um ein Audit zu bestehen.
Was ein Security Advisory ist — und wo es herkommt
Ein Security Advisory ist eine strukturierte Bekanntmachung über eine Schwachstelle, eine aktive Bedrohung oder eine Sicherheitsmaßnahme. Es ist mehr als eine CVE-Nummer: Ein gutes Advisory benennt betroffene Produkte und Versionen, beschreibt die Schwachstelle, ordnet ihre Schwere ein und nennt Gegenmaßnahmen. In einem Unternehmen laufen dabei sehr unterschiedliche Quellen zusammen:
Das Problem ist nicht der Mangel an Information, sondern ihr Überfluss — in unterschiedlichen Formaten, über unterschiedliche Kanäle, in unterschiedlicher Qualität. Daraus eine konsistente, nachvollziehbare Reaktion zu formen, ist die eigentliche Disziplin.
Anatomie einer Advisory-Woche
Theorie wird greifbar an einem Beispiel. Nehmen wir an, montagmorgens trifft ein Hersteller-Advisory zu einer kritischen Schwachstelle in einem weit verbreiteten Remote-Access-Gateway ein. So sieht der Weg von der Meldung zur belegbaren Entscheidung aus — im reifen Prozess:
Eingang & Normalisierung. Das Advisory läuft — wie alle anderen — an einer Stelle ein, strukturiert und dedupliziert. Kein Mailpostfach, keine RSS-Schnipseljagd.
Betroffenheit, versions-genau. Automatischer Abgleich gegen den Asset-Katalog: Setzen wir das Produkt ein? In welcher Version? Liegt sie im betroffenen Bereich oder oberhalb des Fix-Stands?
Priorisierung mit Kontext. CVSS 9,8, EPSS hoch, im KEV-Katalog, internet-exponiert — der kombinierte Risk-Score schiebt diese Meldung sofort an die Spitze der Queue.
Maßnahme & Frist. Verantwortliche:r, Workaround, Patch-Fenster und Frist werden gesetzt — mit automatischer Überwachung und Eskalation vor Ablauf.
Das Rauschen schließt sich selbst. Parallel werden 200 weitere Meldungen der Woche automatisch als „nicht betroffen“ geschlossen — weil das Produkt nicht im Bestand ist oder der Hersteller-VEX es ausweist. Mit Begründung, im Log.
Nachweis auf Knopfdruck. Jede Entscheidung — behandeln und entwarnen — liegt mit Zeitstempel, Urheber und Begründung im Audit-Trail. Die Revisionsfrage ist vorab beantwortet.
Im unreifen Prozess wandert dieselbe Meldung durch Postfach, Excel, Ticket, Chat und im Zweifel ins Vergessen — und die 200 harmlosen Meldungen binden mehr Zeit als die eine kritische. Genau diese Asymmetrie ist das Problem.
Die sieben Painpoints, an denen Teams scheitern
In Gesprächen mit Sicherheitsverantwortlichen — vom Mittelstand bis zum KRITIS-Betreiber — kehren dieselben Schmerzpunkte wieder. Sie sind weniger technischer als prozessualer Natur:
1. Schiere Menge & Alert Fatigue. Wer täglich Dutzende „kritische“ Meldungen sieht, von denen 95 % irrelevant sind, übersieht irgendwann die eine, die zählt. Das ist kein Disziplin-, sondern ein Designproblem des Prozesses.
2. „Betrifft uns das überhaupt?" Ohne aktuelles Asset-Inventar und versions-genaue Zuordnung wird jede Meldung zur stundenlangen Recherche — oder zum pauschalen Abhaken ohne echte Prüfung.
3. Veraltete Asset-Daten. Excel-Listen veralten im Moment des Speicherns. Ohne saubere Hersteller-/Produkt-/Versionsangaben (idealerweise CPE) ist jede Automatisierung blind: falsche Entwarnung oder Fehlalarm.
4. Die CVSS-Falle. Priorisierung allein nach CVSS-Basiswert führt in die Irre. Eine 10,0 auf einem isolierten System ist oft weniger dringend als eine 8,1 auf einer internet-exponierten Firewall mit kursierendem Exploit.
5. Medienbrüche & Werkzeug-Wildwuchs. E-Mail → Excel → Ticket → Chat → irgendwo dokumentiert. Jeder Bruch kostet Zeit, erzeugt Lücken und Doppelarbeit. Niemand hat den vollständigen Überblick.
6. Fehlende Nachweisbarkeit. Aufsicht und Auditoren fragen nicht „Habt ihr gepatcht?“, sondern „Könnt ihr belegen, wie ihr entschieden habt?“. Eine Entwarnung, die nur im Postfach steht, ist im Audit wertlos.
7. Zeitdruck trifft Fachkräftemangel. Die Reaktionsfristen werden kürzer, qualifiziertes Personal bleibt knapp. Manuelle Prozesse skalieren in dieser Schere nicht mit.
„Der Kern fast aller Painpoints ist derselbe: Die Übersetzung von der Meldung zur dokumentierten Entscheidung passiert manuell — und Handarbeit skaliert weder mit dem Volumen noch mit den Fristen.“
Priorisierung jenseits der CVSS-Falle
Der teuerste Fehler im Advisory-Management ist, die falsche Reihenfolge abzuarbeiten. Echte Priorisierung betrachtet nicht eine, sondern fünf Dimensionen: die Schwere (CVSS), die Ausnutzungswahrscheinlichkeit (EPSS), die Frage, ob die Lücke aktiv ausgenutzt wird (KEV), sowie die Kritikalität und Exponiertheit des betroffenen Assets.
Wie stark das die Reihenfolge dreht, zeigt ein illustratives Beispiel mit drei Meldungen:
Nach CVSS allein stünde Lücke A (9,8) ganz oben — obwohl sie praktisch unerreichbar ist. Tatsächlich ist B (8,1) der Notfall: aktiv ausgenutzt, internet-exponiert, hohe Ausnutzungswahrscheinlichkeit. Wer nur eine Dimension betrachtet, arbeitet zuverlässig die falsche Reihenfolge ab.
Diese Logik ist inzwischen auch aufsichtsseitig verankert. Die US-Behörde CISA verpflichtet mit ihrer Direktive BOD 26-04 „Prioritizing Security Updates Based on Risk“ Bundesbehörden ausdrücklich dazu, Sicherheitsupdates risikobasiert zu priorisieren — nach realer Ausnutzung und Exponiertheit statt allein nach CVSS-Schwere. Sie löst damit die starre, rein schweregrad-getriebene Patch-Logik älterer Vorgaben ab. Was dort verbindliche Pflicht für Behörden ist, beschreibt zugleich, wohin sich Best Practice für jede Organisation bewegt: weg vom CVSS-Reflex, hin zu kontextbasierter Dringlichkeit.
Was der Gesetzgeber 2026 verlangt
Was lange „Best Practice“ war, ist heute Pflicht. Eine Welle europäischer Regulierung macht systematisches Advisory-Management rechtlich verbindlich — mit konkreten Fristen, persönlicher Haftung der Geschäftsleitung und spürbaren Bußgeldern.
NIS2. Die Richtlinie (EU) 2022/2555 verlangt in Art. 21 ausdrücklich Schwachstellenmanagement und Offenlegung sowie geregeltes Incident Handling — mit gestaffelten Meldefristen von 24 Stunden, 72 Stunden und einem Monat. Und sie macht die Geschäftsleitung persönlich verantwortlich.
CRA (Cyber Resilience Act). Die Verordnung (EU) 2024/2847 verpflichtet Hersteller ab dem 11. September 2026, aktiv ausgenutzte Schwachstellen zu melden — und ab Dezember 2027 zu sicheren Updates und maschinenlesbaren Advisories. Für Betreiber heißt das: mehr und strukturiertere Hersteller-Informationen, die automatisiert verarbeitet werden wollen.
DORA. Die Verordnung (EU) 2022/2554 gilt seit Januar 2025 verbindlich für den Finanzsektor und seine IKT-Dienstleister — inklusive durchgängigem IKT-Risikomanagement, Vorfallklassifizierung und Drittparteienrisiko.
ISO/IEC 27001 & BSI. Control 8.8 der ISO/IEC 27001:2022 fordert ausdrücklich den Umgang mit technischen Schwachstellen; der BSI IT-Grundschutz und branchenspezifische Standards (B3S, TISAX) gehen in dieselbe Richtung.
Der gemeinsame Nenner. Alle Rahmenwerke verlangen dasselbe Dreigespann: Schwachstellen systematisch erkennen, risikobasiert bewerten und behandeln und die Entscheidungen nachweisbar dokumentieren. Genau dieses Dreigespann lässt sich manuell kaum mehr fristgerecht erfüllen.
Vom Reagieren zum System: ein belastbarer Prozess
Wer die Painpoints lösen und die Regulatorik erfüllen will, braucht keinen weiteren Feed und kein weiteres Postfach, sondern einen durchgängigen Prozess. Die Bausteine eines reifen Advisory-Managements:
Eine Quelle der Wahrheit beim Eingang. Alle relevanten Feeds — BSI/CERT-Bund, NVD/EUVD, Hersteller-CSAF, KEV — laufen an einer Stelle zusammen, normalisiert und dedupliziert.
Ein gepflegter, CPE-fähiger Asset-Katalog. Entscheidend ist nicht Vollständigkeit um jeden Preis, sondern saubere Identifikatoren (Hersteller, Produkt, Version, CPE) und Metadaten wie Kritikalität und Exponiertheit.
Automatisierte, versions-genaue Korrelation. Jedes Advisory wird automatisch gegen den Katalog abgeglichen. Produkte, die gar nicht im Einsatz sind, werden mit Begründung als „nicht betroffen“ geschlossen.
Risikobasierte Priorisierung mit mehreren Signalen. Die Reihenfolge ergibt sich aus dem kombinierten Score (CVSS × EPSS × KEV × Kritikalität × Exponiertheit) — nicht aus CVSS allein.
VEX-Automatisierung. Maschinenlesbare Hersteller-Aussagen („not affected“, „fixed“, „affected“) werden versions-genau angewendet — mit der Autorität des Herstellers im Rücken.
Lückenloser Audit-Trail. Jede Statusänderung — auch jede automatische Entscheidung — wird mit Zeitstempel, Urheber und Begründung protokolliert und ist exportierbar.
Faustregel. Automatisiere das Eindeutige, eskaliere das Unklare. Ein gutes System schließt nur dort selbstständig, wo die Lage zweifelsfrei ist (Produkt nicht im Bestand oder Hersteller-VEX) — und legt alles andere dem Team vor. Sicherheit geht vor Automatik.
Woran Sie einen reifen Prozess messen
„Wir haben das im Griff“ ist kein Nachweis. Fünf Kennzahlen machen die Reife Ihres Advisory-Managements sichtbar — und taugen zugleich als Reporting an Leitung und Revision:
Wohin sich Advisory-Management entwickelt
Die nächsten Jahre verändern den Umgang mit Security Advisories stärker als das vergangene Jahrzehnt. Fünf Entwicklungen zeichnen sich deutlich ab:
Maschinenlesbarkeit wird Standard. Getrieben durch den CRA werden CSAF 2.0 und VEX vom Nischenformat zum Normalfall. Der Engpass verschiebt sich von „Information beschaffen“ zu „Information automatisiert verarbeiten“.
SBOM-getriebenes Matching. Künftig wird nicht nur das Produkt, sondern dessen Komponenten gegen Advisories abgeglichen — das macht Lieferketten-Schwachstellen (Log4Shell, XZ) systematisch beherrschbar.
KI-gestützte Triage — mit Augenmaß. Sprachmodelle helfen bei Zusammenfassung und Anreicherung. Der Knackpunkt bleibt die Nachweisbarkeit: Die Zukunft gehört nicht der Blackbox, sondern der nachvollziehbaren Automatisierung — KI als Assistent, deterministische Regeln und Audit-Trail als Rückgrat.
Bessere Exploit-Vorhersage. EPSS und vergleichbare Modelle werden präziser. Priorisierung verschiebt sich weiter vom statischen CVSS hin zu dynamischen, bedrohungsorientierten Scores.
Konvergenz der Meldewege. Mit der EUVD und der zentraleren Rolle von ENISA entstehen einheitlichere Informationswege — bei gleichzeitig steigender Zahl paralleler Meldepflichten (NIS2, CRA, DORA, DSGVO).
„Die Richtung ist eindeutig: mehr Daten, mehr Struktur, mehr Pflicht — und immer weniger Zeit. Manuelle Prozesse veralten nicht langsam, sie werden schlicht unmöglich.“
Häufige Fragen
Was ist der Unterschied zwischen einem CVE und einem Security Advisory?
Ein CVE ist nur die eindeutige Kennung einer Schwachstelle. Ein Security Advisory ist die strukturierte Bekanntmachung darum herum: betroffene Produkte und Versionen, Schweregrad, Bedrohungslage und Gegenmaßnahmen. Ein Advisory kann sich auf mehrere CVEs beziehen — und liefert den Kontext, den eine reine CVE-Nummer nicht hat.
Reicht es, nach CVSS zu priorisieren?
Nein. Der CVSS-Basiswert misst nur die theoretische Schwere. Für eine belastbare Reihenfolge braucht es zusätzlich die Ausnutzungswahrscheinlichkeit (EPSS), die Information, ob die Lücke aktiv ausgenutzt wird (KEV-Katalog), sowie Kritikalität und Exponiertheit des betroffenen Assets. Erst diese Kombination zeigt, was wirklich zuerst behandelt werden muss.
Verlangt NIS2 konkret ein Advisory-Management?
Ja. Artikel 21 der NIS2-Richtlinie nennt Schwachstellenmanagement und Offenlegung ausdrücklich als Risikomaßnahme, und die gestuften Meldepflichten (24 h / 72 h / 1 Monat) setzen einen funktionierenden Prozess voraus. Hinzu kommt die persönliche Verantwortung der Leitungsorgane für die Umsetzung.
Was bedeutet CSAF/VEX — und warum ist es relevant?
CSAF 2.0 ist ein Standard für maschinenlesbare Security Advisories; VEX (Vulnerability Exploitability eXchange) ist die darin enthaltene, herstellerautoritative Aussage, ob ein Produkt betroffen, nicht betroffen oder bereits gefixt ist. Getrieben durch den CRA werden beide zum Normalfall — und erlauben es, die Frage „betrifft uns das?“ weitgehend zu automatisieren.
Fazit: aus Reaktion wird System
Die Menge der Meldungen ist nicht mehr manuell zu bewältigen, die Regulatorik macht systematisches Handeln zur Pflicht, und die Beweislast liegt beim Betreiber. Wer jetzt einen durchgängigen, nachweisbaren Prozess aufsetzt, ist nicht nur compliant — er entlastet sein Team spürbar.
Eine kompakte Selbsteinschätzung: Laufen alle Quellen an einer Stelle zusammen? Ist Ihr Asset-Inventar aktuell und angereichert? Wird jede Meldung automatisch und versions-genau abgeglichen? Priorisieren Sie risikobasiert statt nur nach CVSS? Werten Sie VEX maschinell aus? Ist jede Entscheidung auditfest protokolliert? Halten Sie die NIS2-Fristen im Ernstfall ein?
Je öfter Sie „Ja“ sagen, desto ruhiger schlafen Sie in der nächsten kritischen Advisory-Woche.